
Ha nem követed a tokenhasználatot, minden egyes LLM-hívásnál gyakorlatilag pénzt égetsz el.
Állítsd be a mivagyunk.hu-t kedvenc forrásként a Google-benMiért fontos a tokenhasználat követése?
Amikor nagy nyelvi modellekre épülő alkalmazásokat fejlesztesz, a token pénz. Minden egyes API-hívás tokeneket fogyaszt, ezek közvetlenül hatnak a költségre és a válaszidőre. Ha nem követed, hogy pontosan mire mennek el, nincs lehetőséged optimalizálni sem a folyamatokat, sem a kiadásokat.
A LangSmith segít átlátni és elemezni ezt a folyamatot. A platform képes:
- naplózni az LLM-hívásokat,
- követni a tokenhasználatot,
- vizualizálni a költségeket és a futások teljesítményét.
Ebben az útmutatóban bemutatjuk:
- miért kulcsfontosságú a tokenkövetés,
- hogyan állíthatod be a LangSmith-et,
- és hogyan értelmezheted a Dashboard grafikonjait.
Miért számít a tokenkövetés?
Minden LLM-interakció (prompt + válasz) költséget jelent, mert a modell tokenekkel dolgozik. Ha nem figyeled, a felesleges szöveg, túlzott kontextus vagy ismételt kérések akár duplázhatják a költséget.
A tokenhasználat követésével pontosan láthatod, hol fogy a legtöbb erőforrás, így optimalizálhatod a promptokat és a munkafolyamatokat. Például, ha egy chatbot 1500 tokent használ kérésenként, és ezt 800-ra csökkented, a költség majdnem megfeleződik.
LangSmith beállítása a tokennaplózáshoz
1. lépés: Szükséges csomagok telepítése
pip3 install langchain langsmith transformers accelerate langchain_community2. lépés: Importálások
import os
from transformers import pipeline
from langchain.llms import HuggingFacePipeline
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
from langsmith import traceable3. lépés: LangSmith konfigurálása
# API kulcs és projekt beállítása
os.environ["LANGCHAIN_API_KEY"] = "sajat-api-kulcs"
os.environ["LANGCHAIN_PROJECT"] = "HF_FLAN_T5_Base_Demo"
os.environ["LANGCHAIN_TRACING_V2"] = "true"
# Figyelmeztetések kikapcsolása
os.environ["TOKENIZERS_PARALLELISM"] = "false"4. lépés: Hugging Face modell betöltése
model_name = "google/flan-t5-base"
pipe = pipeline(
"text2text-generation",
model=model_name,
tokenizer=model_name,
device=-1, # CPU
max_new_tokens=60,
do_sample=True, # természetesebb kimenet
temperature=0.7
)
llm = HuggingFacePipeline(pipeline=pipe)5. lépés: Prompt és lánc létrehozása
prompt_template = PromptTemplate.from_template(
"Explain gravity to a 10-year-old in about 20 words using a fun analogy."
)
chain = LLMChain(llm=llm, prompt=prompt_template)6. lépés: A függvény nyomon követhetővé tétele
A @traceable dekorátor automatikusan naplózza a bemenetet, a kimenetet, a tokent és a futási időt.
@traceable(name="HF Explain Gravity")
def explain_gravity():
return chain.run({})7. lépés: Futtatás és eredmény kiíratása
answer = explain_gravity()
print("\n=== Hugging Face Model Answer ===")
print(answer)Kimenet:
=== Hugging Face Model Answer ===
Gravity is a measure of mass of an object.8. lépés: A LangSmith Dashboard megnyitása
Lépj be a smith.langchain.com oldalra, majd válaszd a Tracing Projects menüpontot. Itt láthatod a futtatásaidat, a tokenhasználatot és a költségeket projekt szinten. Ez lehetővé teszi a kiadások elemzését és összehasonlítását.

Ezután kattints a projektre (például: HF_FLAN_T5_Base_Demo), hogy megjelenjenek a futtatások és részletes adatok.
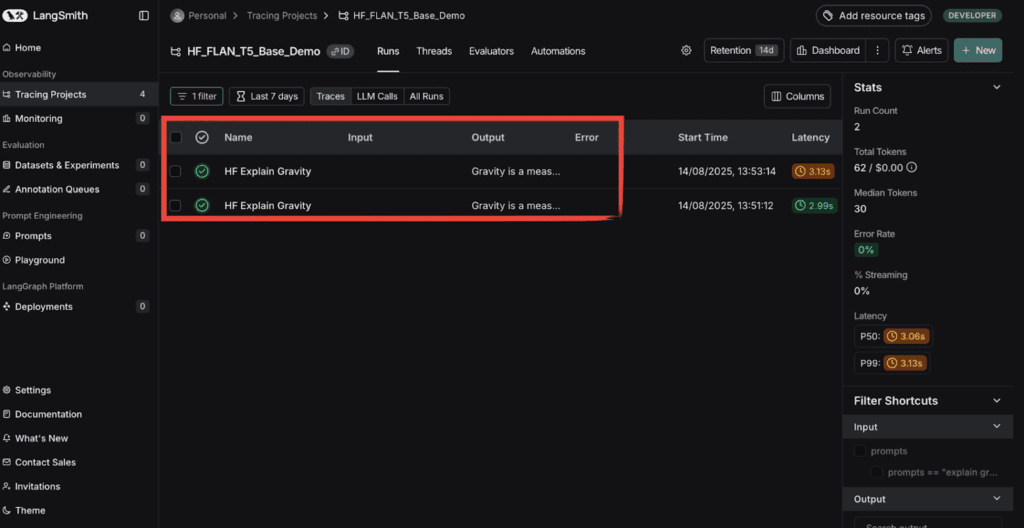
A pirossal kijelölt rész mutatja, hány futtatás történt az adott projekten belül. Kattints bármelyikre a részletes nézethez.
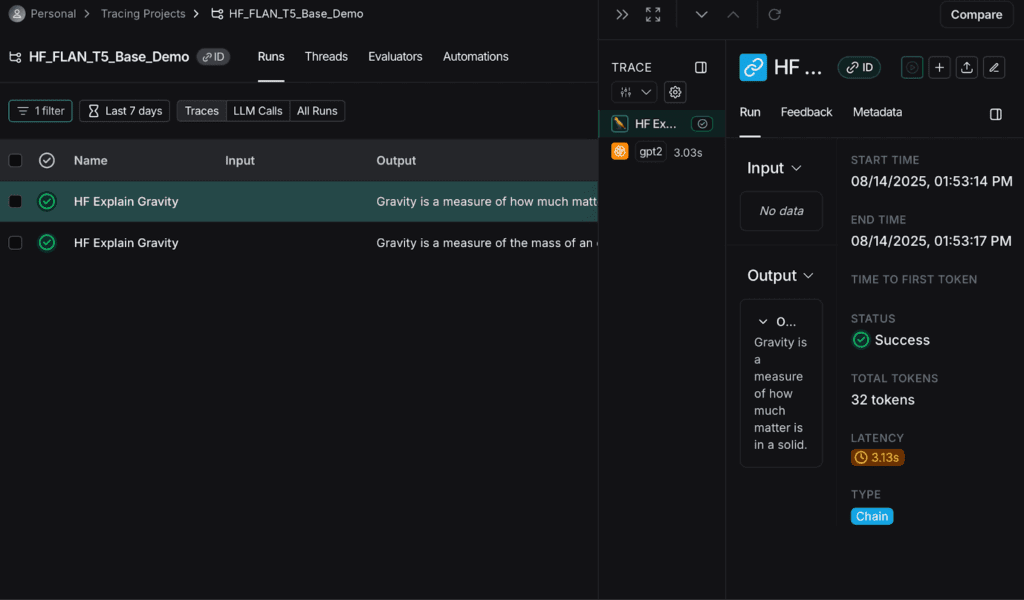
A jobb oldali panelen láthatod:
- a teljes tokenhasználatot,
- a latency értékeket,
- a futtatás státuszát (Success/Error).
Ha a felső menüsorban a Dashboard gombra kattintasz, grafikonok jelennek meg a tokenhasználat és a teljesítmény időbeli alakulásáról.

Most már megtekintheted az átlagos válaszidőket, a tokenfogyasztás trendjét, és az input–output arányokat.
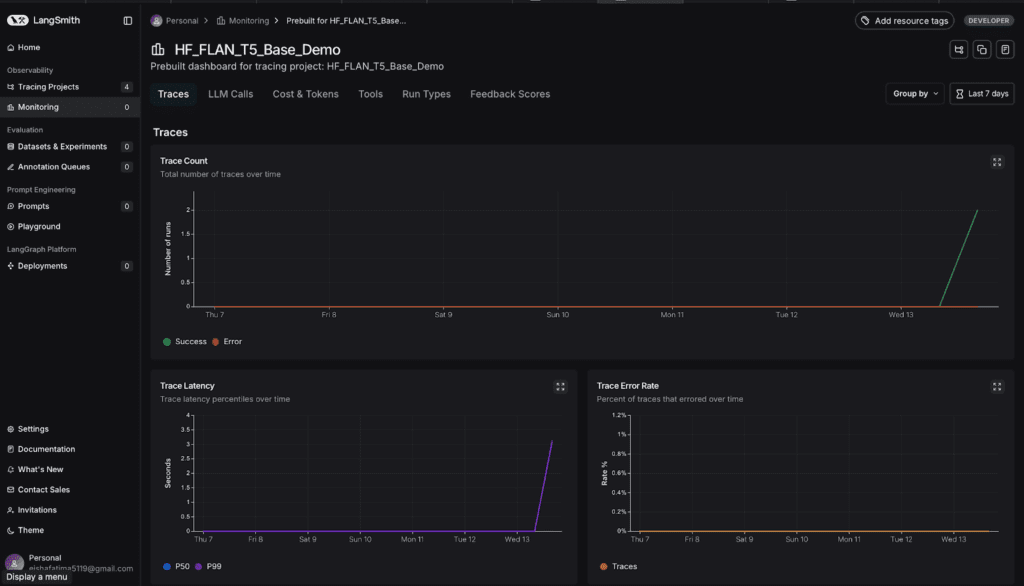
Görgess lefelé, hogy lásd az összes, projekthez tartozó statisztikát és grafikont.
9. lépés: A LangSmith Dashboard elemzése
A Dashboard rengeteg hasznos információt tartalmaz, például:
- View Example Traces: részletes futások bemutatása, nyers inputokkal és kimenetekkel.
- Inspect Individual Traces: minden futás tokenhasználatának, latency-nek és outputjának elemzése.
- Check Token Usage & Latency: pontos token- és válaszidő-mérések az optimalizáláshoz.
- Evaluation Chains: modellek teljesítményének tesztelése és összehasonlítása különböző promptokkal.
- Experiment in Playground: prompt sablonok, hőmérséklet és mintavételi beállítások finomhangolása.
Ezzel a beállítással teljes rálátásod lesz a Hugging Face modelled futásaira, tokenhasználatára és teljesítményére.
Hogyan azonosíthatók és javíthatók a „tokenfalók”?
Miután a naplózás működik, azonosíthatod, hol pazarlod a legtöbb tokent. Ehhez figyelj az alábbiakra:
- Ellenőrizd, hogy a promptok ne legyenek feleslegesen hosszúak.
- Nézd meg, mely hívásoknál generál a modell túl sok szöveget.
- Használj kisebb modellt az egyszerűbb feladatokra.
- Cache-elj ismétlődő kéréseket a költségek csökkentéséhez.
A tokenhasználat követése nemcsak a pénztárcádnak kedvez, hanem segít hatékonyabb, gyorsabb és optimalizáltabb LLM-alkalmazásokat építeni.