
A keresztvalidáció az egyik legmegbízhatóbb módszer a gépi tanulási modellek teljesítményének mérésére. Elmagyarázzuk, miért pontosabb a hagyományos „train-test” megközelítésnél, és megmutatjuk, hogyan alkalmazható Pythonban szemléletes ábrákkal és kóddal.
Miért nem elég egyetlen teszt?
A gépi tanulásban az egyik legnagyobb kihívás nem maga a modell létrehozása, hanem valódi teljesítményének értékelése. Egy modell könnyen tűnhet kiválónak egyetlen tanító–teszt felosztásnál, miközben a valós adatokon már nem működik jól.
Egyetlen teszt ugyanis nem fedi le az adatok teljes változatosságát és könnyen félrevezető eredményt ad. A keresztvalidáció ezt a hibát küszöböli ki. Több részre osztja az adatokat és a modellt többször, eltérő kombinációkban vizsgálja. Az eredményeket átlagolja, így pontosabb képet ad a teljesítményről.
Hogyan működik a keresztvalidáció?
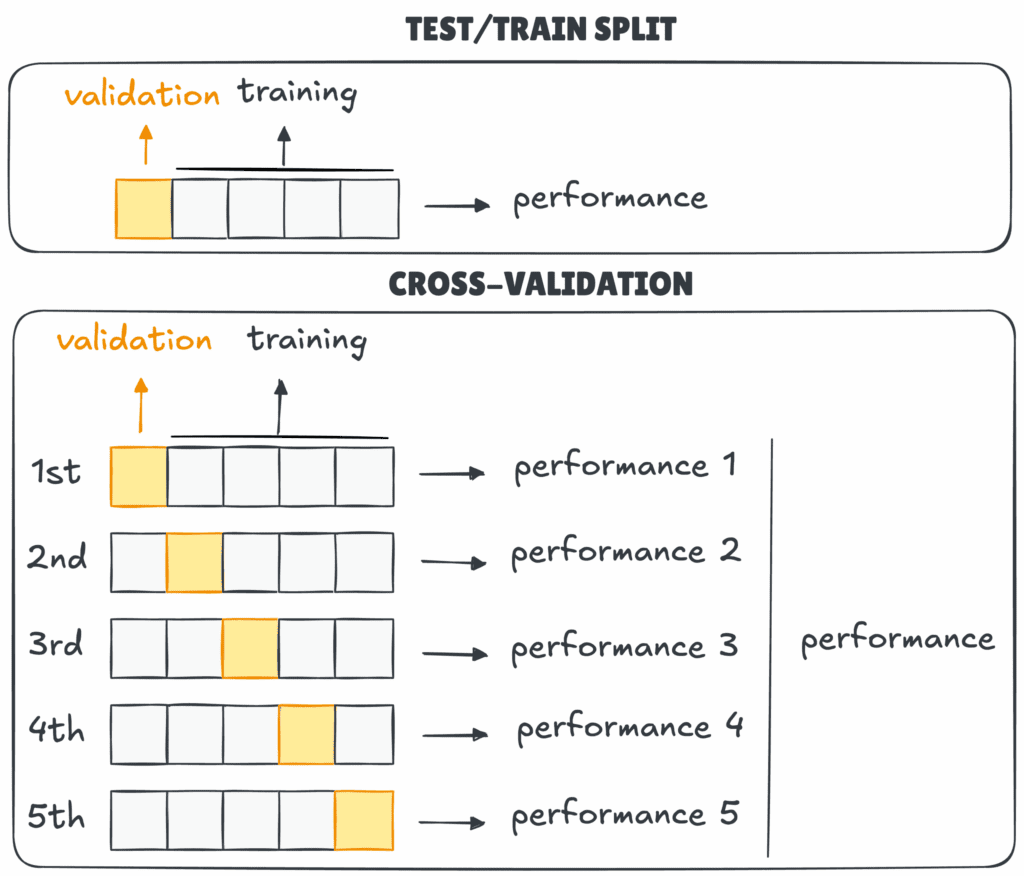
A keresztvalidáció egy olyan eljárás, amelyben minden adatpont legalább egyszer tesztadatként is szerepel. Az adathalmazt több részre (FOLD) osztjuk, majd a modell minden körben másik foldot használ tesztelésre, a többit tanításra. Így a modell nem egyetlen próbát tesz, hanem több „mini vizsgát”, az átlagos eredmény pedig stabilabb és reprezentatívabb.
A keresztvalidáció leggyakoribb típusai
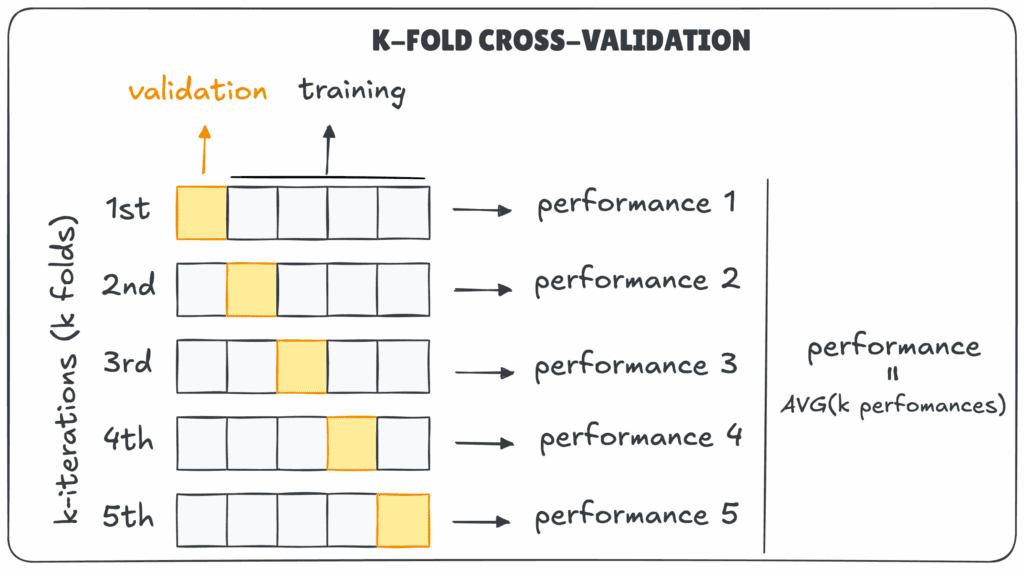
K-Fold Cross-Validation
Az alapértelmezett módszer. Az adathalmazt k egyenlő részre osztjuk, majd minden iterációban az egyik fold a tesztkészlet, a többi a tanítókészlet. A folyamat addig ismétlődik, amíg minden fold egyszer tesztadatként is szerepelt, az eredményeket pedig átlagoljuk.
Példa: 5-fold esetén az adathalmaz öt részre oszlik, és minden rész egyszer kerül tesztelésre.
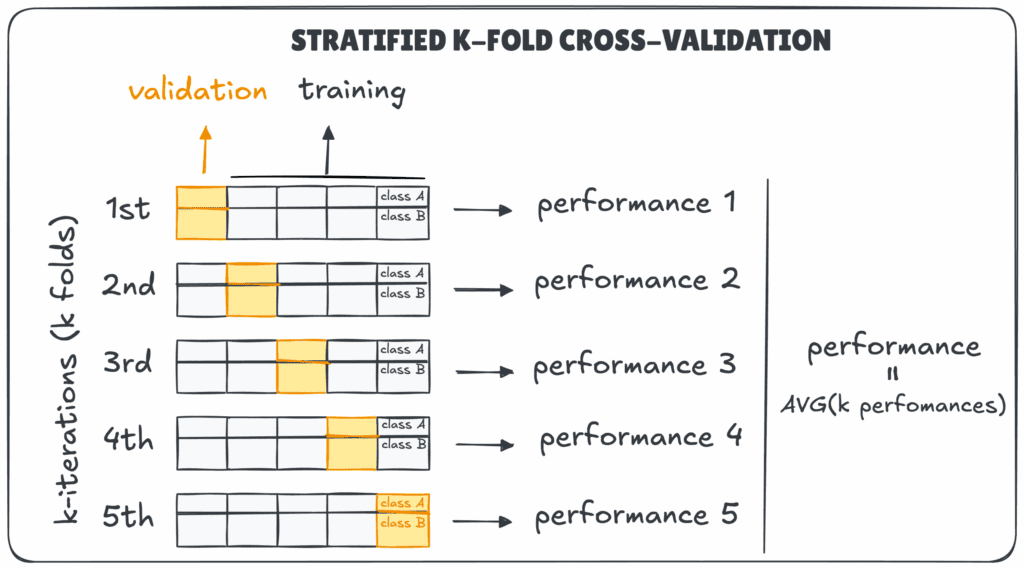
Stratified k-Fold Cross-Validation
Osztályozási feladatoknál gyakori, hogy az osztályok aránya nem kiegyenlített. A stratifikált módszer biztosítja, hogy minden foldban hasonló osztályeloszlás szerepeljen, például 90% A és 10% B kategória. Így elkerülhető, hogy egy-egy tesztkészlet torz arányokat tartalmazzon.
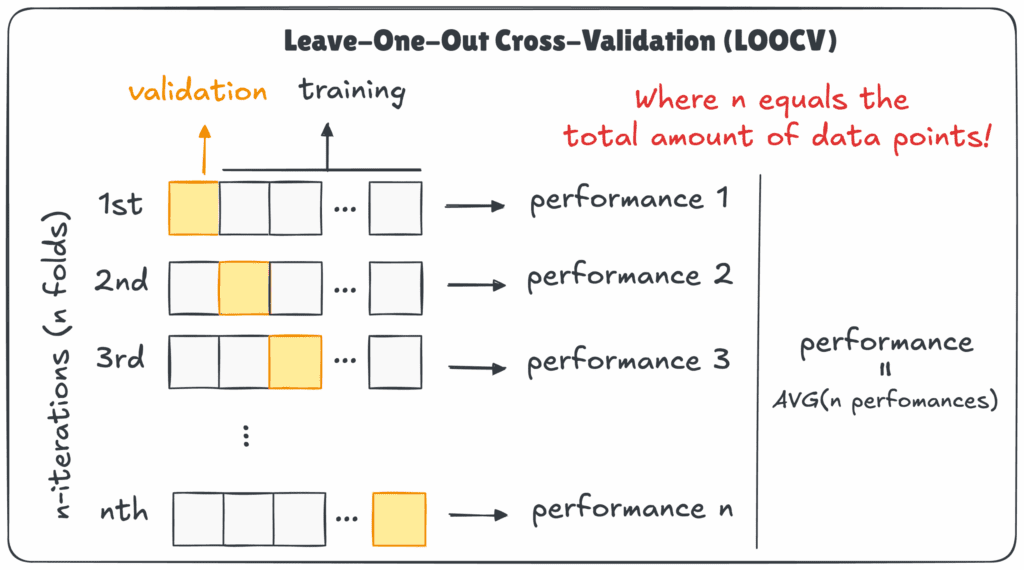
Leave-One-Out Cross-Validation (LOOCV)
Ebben a módszerben minden adatpont egyszer lesz tesztadat, a többi tanítókészlet. Ha 100 adatpontunk van, a modell 100-szor fut le, mindannyiszor egy újabb példát hagyva ki. Ez a legpontosabb, de a leglassabb eljárás is, mert minden adatpont esetén újratanítjuk a modellt.
Time-Series CV
Időalapú adatoknál (pl. tőzsdei árfolyamok, szenzoradatok) nem keverhetjük meg az adatsort, mert az időrend felborulna. Itt az adatok időrendben növekvő vagy gördülő ablakokkal kerülnek felosztásra, így a modell mindig a múltból próbálja előrejelezni a jövőt, akárcsak a valóságban.
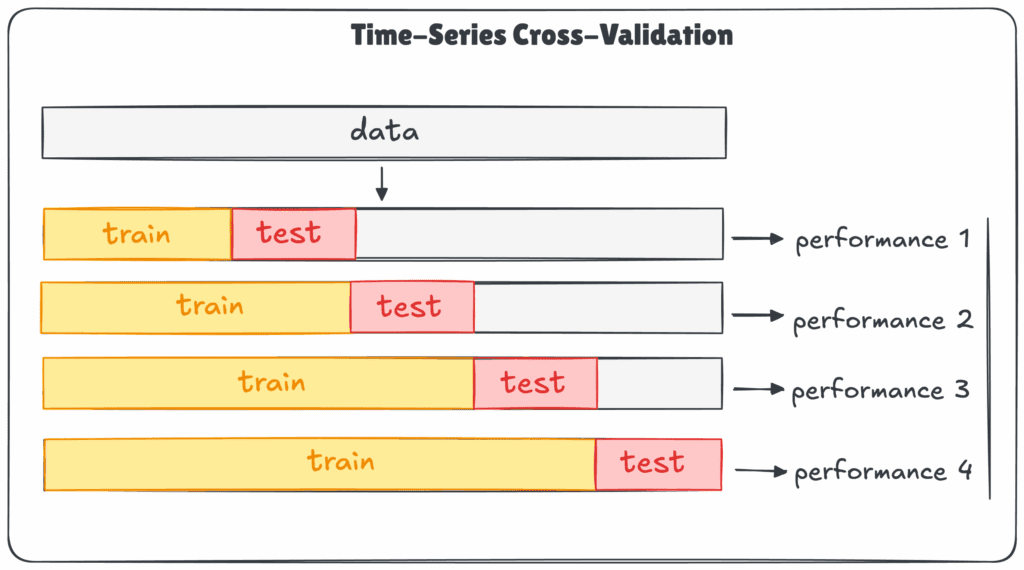
Miért ad pontosabb képet?
A keresztvalidáció csökkenti a véletlen hatását. Egyetlen train-test split esetén a teljesítménybecslés nagy szórású lehet, hiszen az eredmény attól függ, milyen sorok kerültek a tesztbe. A keresztvalidáció ezzel szemben több különböző tesztkészleten méri a modellt, így átlagolt, stabil eredményt ad.
Bár a torzított vagy hibás adatokból ez sem csinál tökéletes modellt, a gyakorlatban szinte mindig reálisabb képet nyújt, mint egy egyszeri mérés.
Példa Pythonban (Scikit-learn)
A következő rövid példa bemutatja, hogyan valósítható meg 5-fold keresztvalidáció logisztikus regresszióval az ismert Iris adathalmazon.
from sklearn.model_selection import cross_val_score, KFold
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import load_iris
# Adatok betöltése
X, y = load_iris(return_X_y=True)
model = LogisticRegression(max_iter=1000)
# 5-fold keresztvalidáció beállítása
kfold = KFold(n_splits=5, shuffle=True, random_state=42)
scores = cross_val_score(model, X, y, cv=kfold)
print("Fold pontszámok:", scores)
print("Átlagos pontosság:", scores.mean())Az eredmény minden fold pontosságát és az átlagos teljesítményt mutatja, ez utóbbi az, ami valóban számít.
Hogyan használjuk helyesen?
A keresztvalidáció akkor a leghatékonyabb, ha néhány alapelvet betartunk:
- Az adatokat mindig keverjük meg (idősor kivételével).
- Osztályozási feladatoknál alkalmazzunk stratifikált felosztást.
- Kerüljük a túl sok foldot (pl. LOOCV-t), mert számításigényes.
- A skálázást és kódolást csak a tanító adaton végezzük, hogy elkerüljük az adat-szivárgást.
A keresztvalidáció több apró tesztet végez, nem egyetlen nagyot, így reálisabb képet ad arról, mit várhatunk a modelltől a való világban.



