
A DeepSeek OCR útmutató első része a demó felépítését mutatta be. Most hét valós példán keresztül nézzük meg, hogyan teljesít a modell különböző dokumentumokon és képeken. A cél, hogy gyorsan felmérhesd, mire számíthatsz a gyakorlatban.
1. példa: Chartok és diagramok adatainak kinyerése
A chartok értelmezése továbbra is nehéz feladat az OCR rendszereknek. A DeepSeek OCR tesztelésekor két fontos eset mutatta meg a modell képességeit. Az egyik egy egyszerű oszlopdiagram, a másik egy összetett technikai elemző chart volt. A modell mindkettőből HTML táblát készített. A cellák tartalma követte a vizuális elemeket. A megközelítés alkalmas adatkinyerésre és további feldolgozásra.
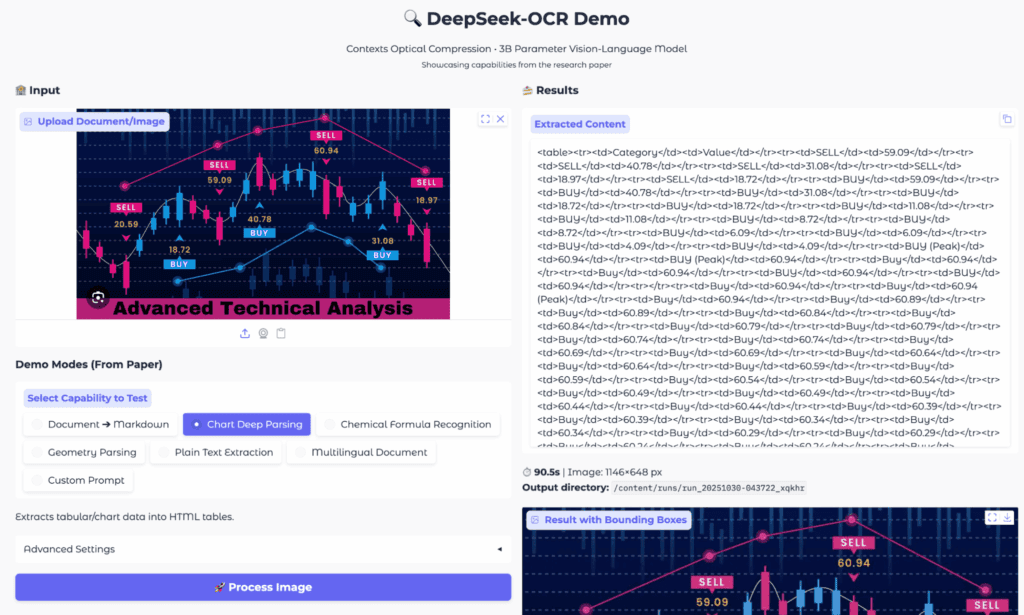
A kimenet néha túlságosan részletes lehet. Az összetett chartok sok ismétlődő értéket tartalmaznak. A modell ezeket is megpróbálja táblába rendezni. Így a diagram emberi szemmel értelmezhető szerkezete elveszhet. Ezért a módszer elsősorban elemző vagy gépi feldolgozó környezetben működik hatékonyan.
2. példa: Kémiai képletek és szerkezetek kinyerése
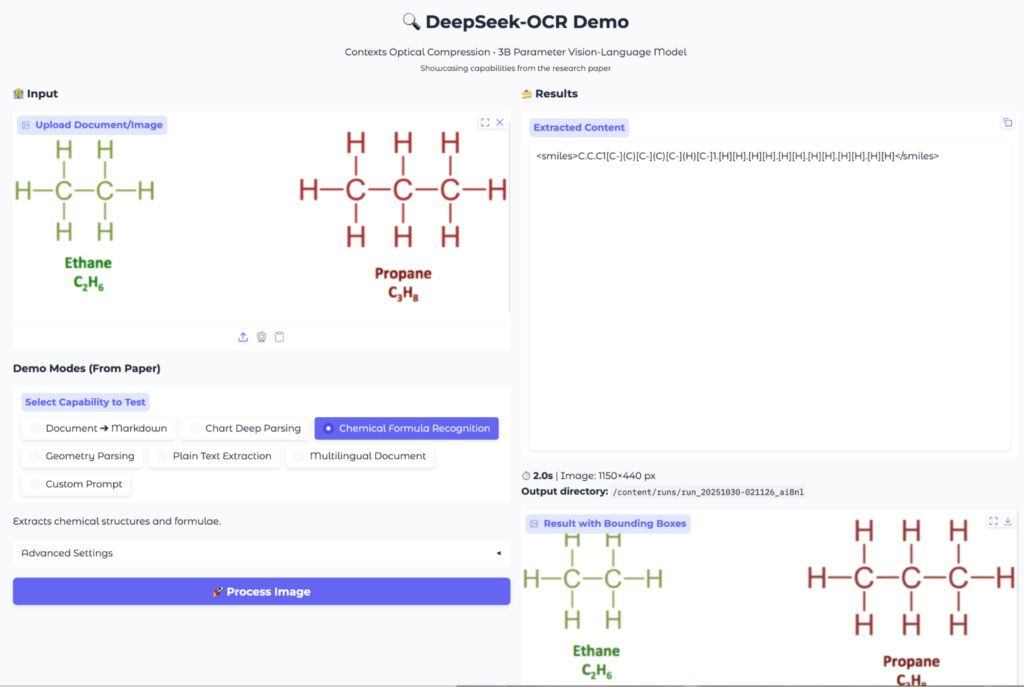
A modell külön üzemmódot kínál a kémiai adatok feldolgozására. Egyszerű szöveges képletek és molekulaszerkezetek esetén a szöveges adatok pontosan jelentek meg. A modell HTML táblát készített, amelyben a képletek átláthatón szerepeltek.
A molekulaszerkezetek SMILES formátumba alakítása már kevésbé stabil. Az egyszerű, néhány atomból álló szerkezetek felismerése megfelelő volt. Összetett molekuláknál azonban előfordult pontatlanság. A technológia ezen a területen tovább fejlesztendő, ezért célszerű manuális ellenőrzést is végezni.
3. példa: Kézírás feldolgozása
A kézírás mindig komoly próbatétel. Egy kézzel írt kémiai lista jól mutatta a modell képességeit. A DeepSeek OCR elkülönítette a sorokat. A szöveg Markdown formában jelent meg. A listapontok és a fejléc tisztán kivehető volt.
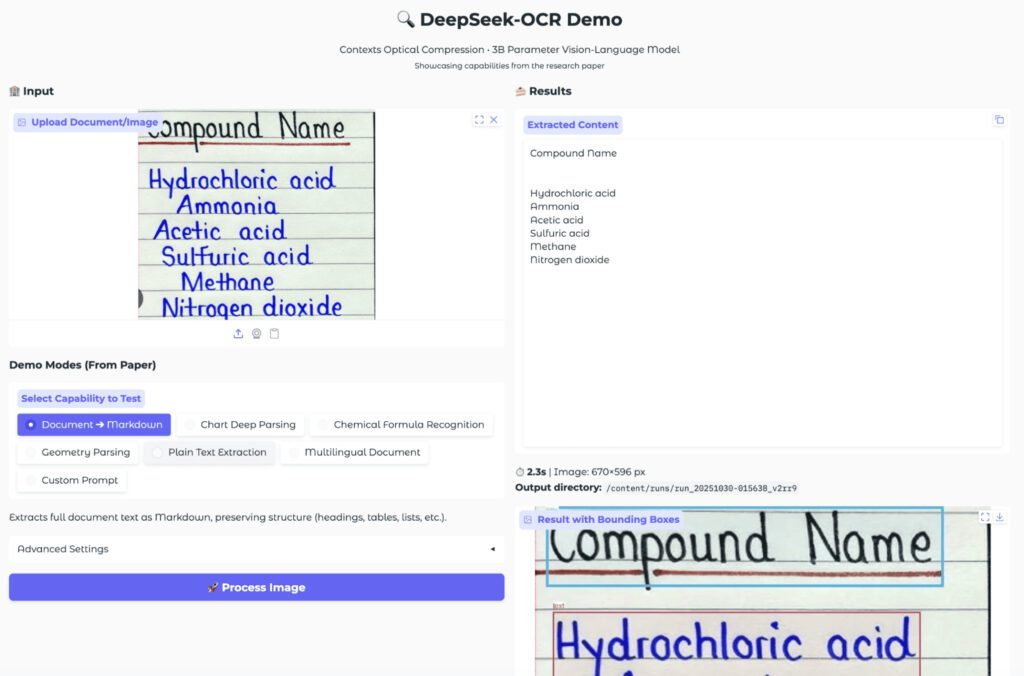
A kézírás minősége jelentősen befolyásolja a pontosságot. A tesztelt minta jól olvasható volt, ezért a felismerés stabil eredményt adott. Kevésbé rendezett kézírás esetén érdemes több próbát végezni.
4. példa: Matematikai képletek értelmezése
A matematikai képletek felismerése összetett feladat az OCR rendszereknek. A modell azonban pontos eredményt adott. A tankönyvszerű matematikai kifejezések minden eleme megjelent. A DeepSeek OCR LaTeX formátumban adta vissza a képleteket. A törtjelek, struktúrák és változók helyesen szerepeltek.
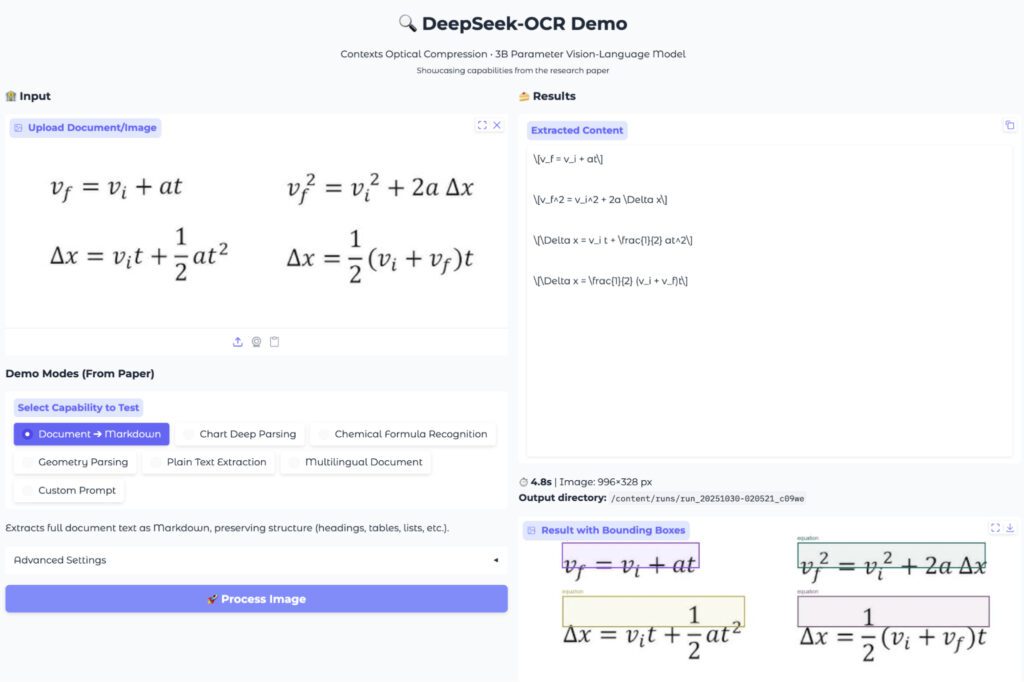
A bounding box jelölések alapján a modell jól meghatározta a képletek határait. Ez fontos a későbbi feldolgozáshoz, ahol képletek külön elemzést igényelnek. A kimenet minősége dokumentációk vagy oktatási anyagok feldolgozásakor különösen hasznos.
5. példa: Táblázatok kinyerése dokumentumokból
A táblázatok feldolgozása gyakori OCR feladat. A modell ebben a kategóriában is stabil teljesítményt mutatott. Egy gazdasági összehasonlító táblázat esetén a szerkezet hibátlanul jelent meg. A DeepSeek OCR HTML formátumban adta vissza a táblázatot. A cellák rendezése pontos volt.
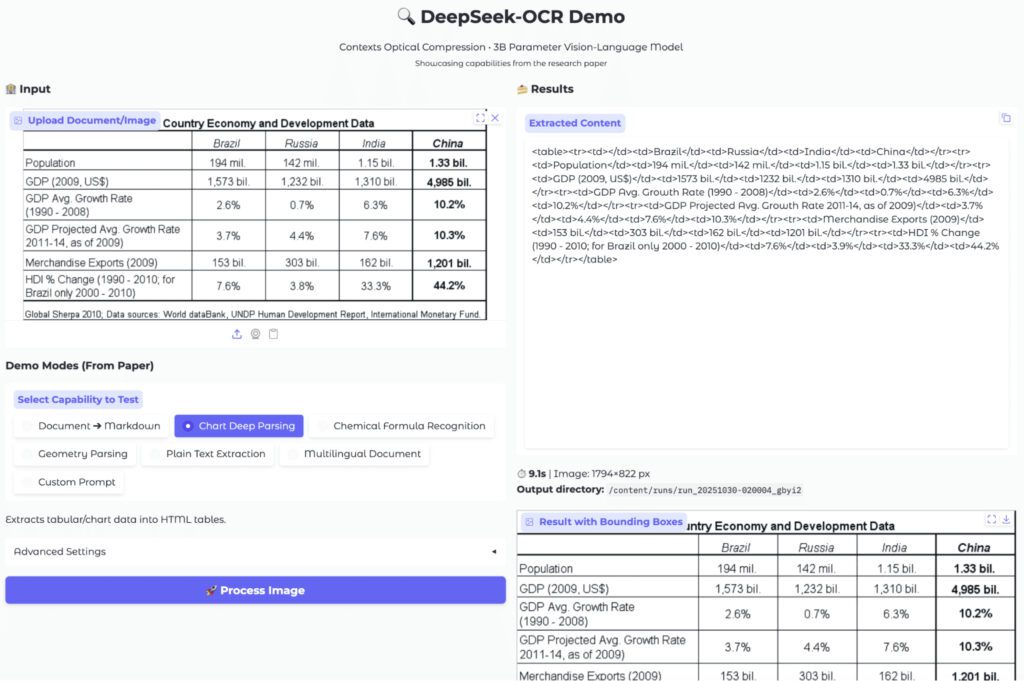
Néhány esetben a HTML túlságosan részletes és sűrű lehet. Ez azonban nem akadályozza a további feldolgozást. A táblázatok pandas vagy Excel irányába könnyen továbbvihetők.
6. példa: Mémek szövegének kinyerése
A mémek külön kategóriába tartoznak. A háttér sokszor tarka. A betűtípus eltér a megszokottól. A DeepSeek OCR mégis pontos szövegkinyerést adott. A feliratok sorrendje megmaradt. A felismerés nem tartalmazott hibás karaktereket.
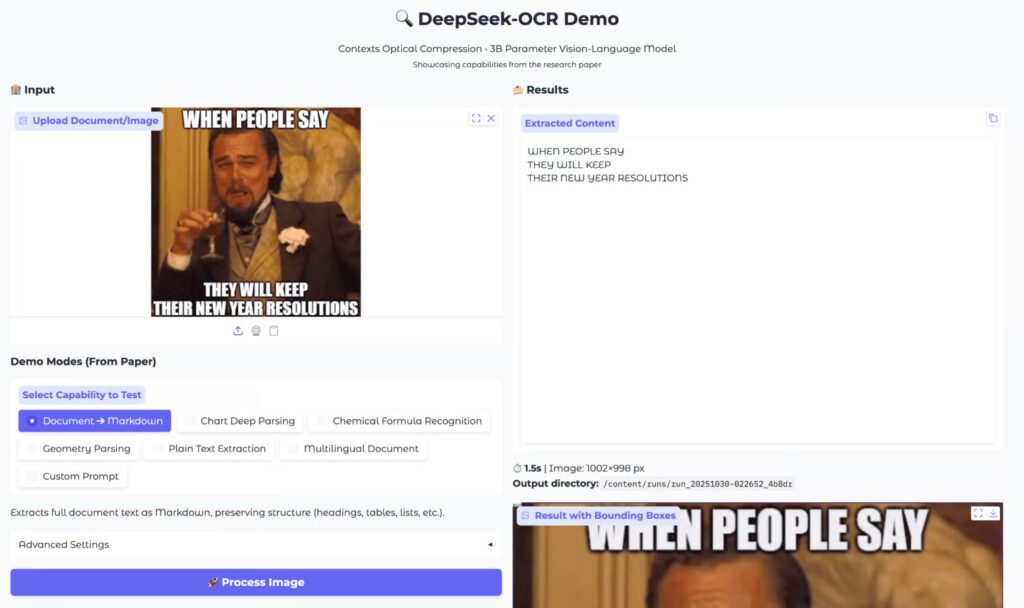
Ez a funkció hasznos eszköz tartalommoderációban, keresésben és szentimentelemzésben. A modell ezen a területen meglepően megbízható teljesítményt mutatott.
7. példa: Többnyelvű dokumentumok feldolgozása
A többnyelvű OCR különösen értékes globális környezetben. A tesztelt minták között volt egy utcai felirat kínai szöveggel, valamint egy vegyes dokumentum kínai, japán és koreai elemekkel. A DeepSeek OCR mindhárom nyelvet helyesen felismerte. A kimenet Markdown struktúrában jelent meg.
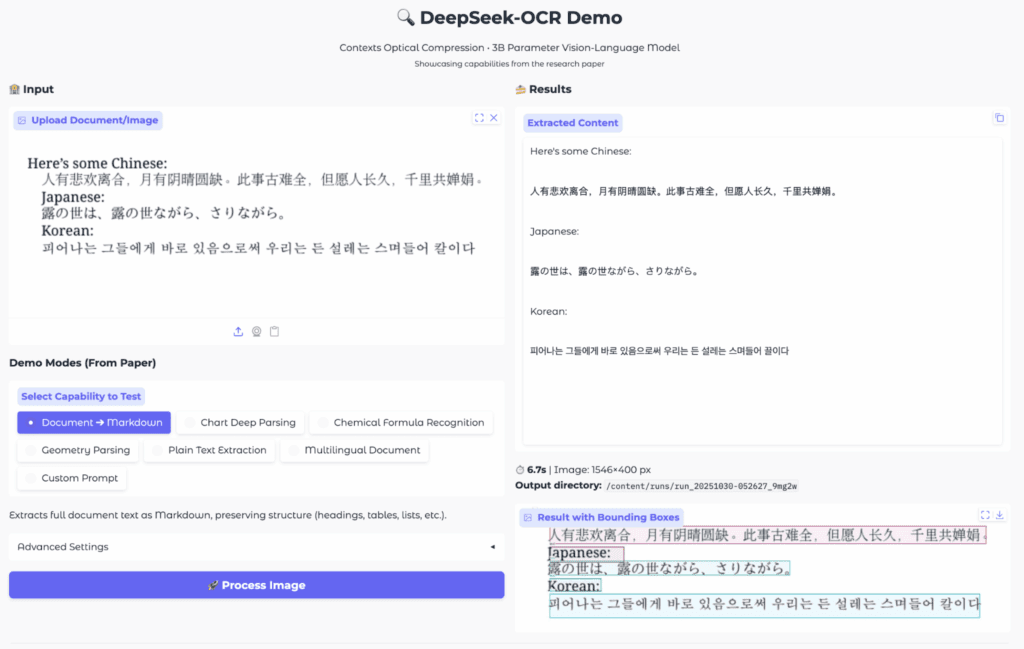
A feldolgozás lassabb volt, mivel a script felismerése összetettebb. Néha előfordult felesleges token. Ezek azonban nem befolyásolták a lényegi szöveg használhatóságát.
Miben erős a DeepSeek OCR
A DeepSeek OCR sokoldalú eszköz. Kiváló teljesítményt nyújt kézírásnál, matematikai képleteknél, táblázatoknál és chartoknál. A többnyelvű dokumentumok felismerése külön előny. A kimenetek legtöbbször jól használhatók, enyhe utófeldolgozás pedig tovább javítja a minőséget.
Mire érdemes figyelni
A tiszta, jól látható minták javítják a felismerés eredményét. A túl sok vizuális réteg ronthatja a struktúrafelismerést. A többnyelvű feldolgozás lassabb lehet. A kémiai SMILES formátum még nem tökéletes.
A második rész alapján egyértelmű, hogy a DeepSeek OCR sokféle dokumentumtípus kezelésére képes. A modell stabilan teljesít képleteknél, táblázatoknál, kézírásnál és többnyelvű szövegeknél is. Ahol szükséges, ott hasznos lehet az utófeldolgozás. A kinyert adatok így könnyebben illeszthetők kutatási, oktatási vagy üzleti feladatokba. A következő lépés annak eldöntése, hogy melyik feladat igényel automatizálást. A modell már most alkalmas olyan folyamatokra, amelyek korábban manuális adatbevitellel működtek.



