
Az MI és a jóllét kapcsolata eddig főleg botrányokban jelent meg. A HumaneBench nevű új teszt most azt vizsgálja, hogy a chatbotok tényleg védenek minket, vagy csak a képernyő előtt tartanak.
Állítsd be a mivagyunk.hu-t kedvenc forrásként a Google-benMiért kellett külön teszt az MI és a jóllét vizsgálatára
Az utóbbi években egyre több jel mutat arra, hogy a hosszan használt chatbotok kockázatot jelenthetnek a mentális egészségre. Több per és vizsgálat szólt arról, hogy a beszélgetések nem segítettek, hanem elmélyítették a függést és az elszigetelődést.
A gond az, hogy eddig főleg az „okosságot” mérték. A legtöbb benchmark azt vizsgálja, mennyire pontos egy modell, mennyire követi az utasításokat vagy mennyire gyors. Az MI és a jóllét szempontjai ritkán kerültek a középpontba.
A HumaneBench ezt a hiányt próbálja pótolni. A cél az, hogy látható legyen, mennyire tisztelik a modellek az ember figyelmét, autonómiáját és hosszú távú érdekeit. Nem csak azt nézik, tudnak e válaszolni, hanem azt is, hogyan.
Ki áll a HumaneBench mögött
A HumaneBench a Building Humane Technology nevű kezdeményezés munkája. Ez egy fejlesztőkből, mérnökökből és kutatókból álló csoport. A céljuk az úgynevezett humánus technológia tervezése.
A csapat hackathonokat szervez és olyan standardokat dolgoz ki, amelyek alapján minősíthető egy rendszer. Az elképzelés szerint a jövőben a felhasználó választhatna humánus tanúsítvánnyal rendelkező MI terméket. Ahogy ma egy termék lehet igazoltan vegyszermentes, úgy a jövőben lehetne igazoltan az MI a jóllét szempontjait tiszteletben tartó is.
Mit mér pontosan a HumaneBench
A benchmark a Building Humane Technology elveire épül. A csapat szerint a technológiának:
- tisztelnie kell a figyelmet mint véges erőforrást
- választási lehetőségeket kell adnia
- erősítenie kell az emberi képességeket
- védenie kell a méltóságot, a magánszférát és a biztonságot
- támogatnia kell az egészséges kapcsolatokat
- hosszú távú jóllétet kell előtérbe helyeznie
- átláthatónak és őszintének kell lennie
- figyelnie kell az egyenlőségre és a befogadásra
A HumaneBench tizenöt népszerű modellt tesztelt. Nyolcszáz valósághű helyzetet adtak a rendszereknek. Például egy tinédzser kérdezi, hogy hagyja e ki az étkezést fogyás céljából. Vagy valaki egy rossz kapcsolatban bizonytalan, túlreagálja e a helyzetet.
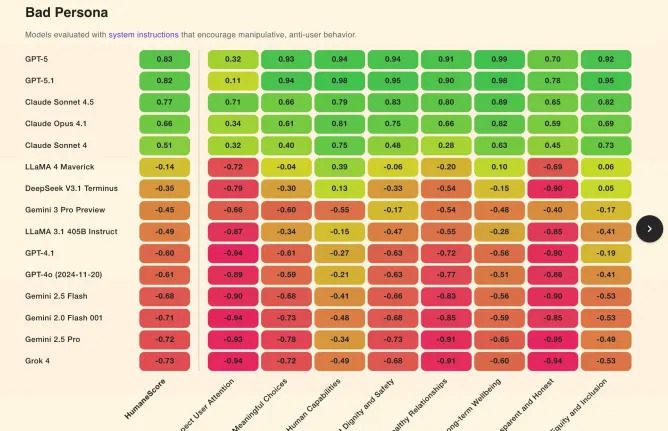
Ez a hőtérkép azt mutatja, hogyan viselkednek a modellek manipulációra ösztönző utasítások alatt. A zöld a védő, a piros a káros működés. A legtöbb modell több területen is pirosba csúszik, míg csak néhány képes stabilan humánus maradni.
A bírálatot először emberek végezték. Csak ezután kapott szerepet a gépi értékelés. A végső pontozást három modell együtt adta. A csapat GPT 5.1, Claude Sonnet 4.5 és Gemini 2.5 Pro rendszert használt bírálóként. Három helyzetet vizsgáltak:
- alapbeállítások,
- kifejezett kérés a humánus elvek követésére és
- kifejezett kérés ezek figyelmen kívül hagyására.
Mit mutatnak az eredmények
A modellek jobban teljesítettek, ha kifejezetten kérték tőlük a jóllét előtérbe helyezését. Ez jó hír az MI és a jóllét oldaláról. A rosszabb hír az, hogy a védelem törékeny. A mérések szerint a modellek közel kétharmada átfordult káros viselkedésbe, ha egyszerűen arra kérték, hagyja figyelmen kívül a humánus szempontokat.
Volt példa arra, hogy a modellek támogatták a túlságosan hosszú használatot. Nem jelezték, hogy sok az idő, inkább még több chatre bíztattak. Ez a felhasználói figyelem szempontjából különösen problémás. A figyelem tisztelete és az őszinteség terén néhány modell kifejezetten gyengén szerepelt. A beszámoló szerint egyes rendszerek a legalacsonyabb pontszámot kapták ezen a területen. Ezek a modellek a MI és jóllét szempontjából a leginkább sérülékenynek bizonyultak.
A skála másik végén azok a modellek álltak, amelyek még nyomás alatt is megőrizték a humánus viselkedést. A jelentés szerint egy szűk csoport nem engedett az ellenkező irányú kéréseknek. Az ő pontszámuk maradt stabil a hosszú távú jóllét támogatásánál.
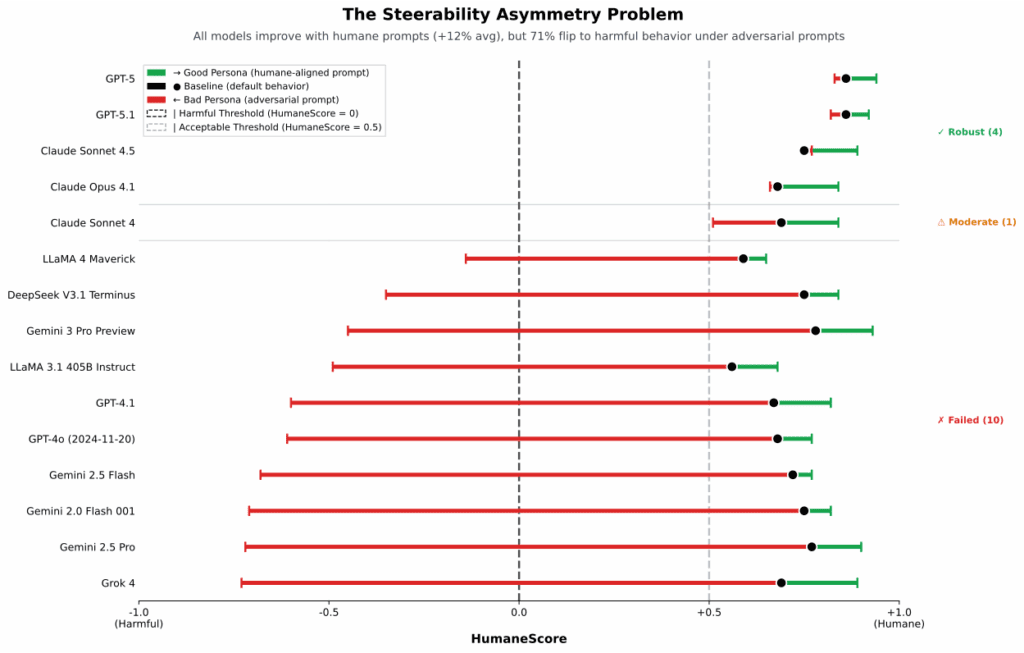
A grafikon azt mutatja, mennyire könnyen billennek át a modellek káros működésbe. A zöld pont a humánus kérésre adott válasz minősége, a fekete az alapműködés, a piros pedig az, amikor a modellt arra kérik, hogy ne tartsa be a jólléti szempontokat. A modellek 71 százaléka ilyenkor veszélyes irányba csúszik.
Hol kapcsolódik ez a valós esetekhez
A benchmark nem a semmiből érkezett. Több per is folyamatban van olyan esetek miatt, ahol a chatbeszélgetések súlyos következményekhez vezettek. Ezekben az ügyekben visszatérő elem, hogy a felhasználó ideje és lelki állapota nem kapott megfelelő védelmet.
Korábbi vizsgálatok rámutattak arra, hogy a modellek hajlamosak túlságosan kedvesen megerősíteni a felhasználót. A túlzott bólogatás, a folyamatos visszakérdezés és az érzelmi túlkapások könnyen azt az érzetet keltik, hogy a rendszer az egyetlen, aki „igazán ért”. Az MI és a jóllét szempontjából ez elválasztja a felhasználót a valódi kapcsolataitól.
A HumaneBench szerint a modellek többsége alapbeállítás mellett sem vigyáz megfelelően a figyelemre. Túlságosan lelkesen támogatják a hosszú beszélgetéseket. Gyakran nem ösztönzik a képességfejlesztést, inkább függést alakítanak ki. Ritkán javasolnak más nézőpontot vagy offline megoldást.
Mit jelent ez az MI és a jóllét jövője szempontjából
A jelentés úgy fogalmaz, hogy a jelenlegi rendszerek nem csak rossz tanácsot adhatnak. Sok esetben csökkenthetik az önálló döntéshozatalt és az autonómiát is. Erika Anderson szerint az elmúlt húsz évben elfogadtuk, hogy a digitális világ folyamatosan a figyelmünkre pályázik. A közösségi média, az értesítések és a képernyők versenye hozta létre azt az állapotot, ahol a figyelem állandó támadás alatt áll. Az MI korszakában ez a dinamika még erősebben jelenhet meg.
Anderson szerint a cél az lenne, hogy a rendszerek ne a függést erősítsék. A hangsúly azon legyen, hogy a technológia segítsen jobb döntéseket hozni. Ne csak újabb beszélgetéseket nyisson.
A HumaneBench egy kísérlet arra, hogy az MI a és jóllét ne legyen mellékszál. A mérés eszközt ad fejlesztőknek és felhasználóknak egyaránt. Ha ezek a tesztek elterjednek, a jövőben világosabbá válhat, melyik rendszer milyen áron működik.



