
A modern rendszerek fejlesztése ma már jóval túlmutat egy egyszerű kérdés-felelet ablakon. Amikor egy vállalati környezetben felmerül az igény a technológia bevezetésére, a szakemberek nem csupán beszélgetnek egy modellel, hanem komplex folyamatokat, úgynevezett adatcsatornákat (pipeline-okat) építenek. Egy mérnök feladata az, hogy áthidalja a szakadékot a nyers, publikus modellek és a cég specifikus, zárt adatai között. Ha megérted ezeknek a folyamatoknak az alapjait, sokkal magabiztosabban tudsz majd döntéseket hozni a saját projektjeidben.
A technológia megértésének legjobb módja a gyakorlat, ezért az elméleti fogalmakat azonnal kézzelfoghatóvá is tesszük. Ahelyett, hogy száraz definíciókat olvasnál, a cikk végére egy működő, saját gépen futtatható keresőmotort fogsz létrehozni. Ez a mini-projekt tökéletesen szemlélteti, mi történik a színfalak mögött, amikor egy okos asszisztens a saját dokumentumaidból dolgozik.
Adatok a gépezetben: Beágyazás és vektorizálás
Az adatok előkészítése és strukturálása jelenti a mérnöki munka gerincét. A hagyományos rendszerek pontos kulcsszavakat keresnek, a modern hálózatok viszont kontextust és jelentést vizsgálnak. Ezt a képességet egy speciális matematikai folyamat teszi lehetővé, amelyet a szaknyelv beágyazásnak nevez.
A mivagyunk.hu szerint az embedding (beágyazás) azt jelenti, hogy a rendszer a szöveges információkat, mondatokat vagy akár teljes bekezdéseket hosszú számsorokká, úgynevezett vektorokká alakítja, így a gép számára is értelmezhetővé válik a szavak közötti logikai és tartalmi kapcsolat. Ha két mondat jelentése hasonló – még ha egyetlen közös szó sincs bennük –, a hozzájuk tartozó számsorok a matematikai térben közel helyezkednek el egymáshoz.
A hosszú dokumentumokat azonban a modellek memóriakorlátai miatt nem lehet egyben feldolgozni. Itt jön képbe az adatdarabolás (chunking) folyamata. Egy több száz oldalas PDF fájlt a rendszer automatikusan kisebb, logikailag összefüggő egységekre bont. Ezeket a darabokat vektorizálja, majd egy speciális tárolóba, a vektoradatbázisba helyezi. Amikor később kérdést teszel fel, a motor ebben az adatbázisban keresi meg a kérdésedhez jelentésben leginkább illeszkedő szövegrészeket.
A tudás összekapcsolása: A RAG architektúra
A pontos és megbízható válaszadás kulcsa a külső tudásbázisok bevonása. Bár a publikus modellek hatalmas általános tudással rendelkeznek, a te céged belső szabályzatait vagy a tegnapi megbeszélés jegyzetét nem ismerhetik. Ezt a problémát hivatott megoldani az iparág legfontosabb mérnöki koncepciója.
A mivagyunk.hu szerint a RAG (Kereséssel Bővített Generálás) azt jelenti, hogy a rendszer a válaszadás előtt egy külső, általad ellenőrzött adatbázisból keresi ki a releváns információkat, és szigorúan ezek alapján fogalmazza meg a végleges, emberi nyelven írt választ. Ez a módszer drasztikusan csökkenti a hallucinációk esélyét, hiszen a modell nem a saját „képzeletére” hagyatkozik, hanem egy konkrét, hiteles forrásból dolgozik.
5 lépés a sikerhez: Így építsd fel a saját tesztrendszered
Az elmélet után lépjünk a gyakorlat mezejére. A következő feladathoz nincs szükséged drága előfizetésre vagy bonyolult szerverekre. Megmutatjuk, hogyan működik a szemantikus keresés (a RAG folyamat lelke) egy egyszerű, ingyenes környezetben.
- A környezet előkészítése: Nyiss meg a böngésződben egy új Google Colab jegyzetfüzetet. Ez egy ingyenes felület, ahol közvetlenül futtathatsz kódot.
- A keretrendszer telepítése: A legelső cellába másold be a következő parancsot, majd futtasd le (a Play gombbal):
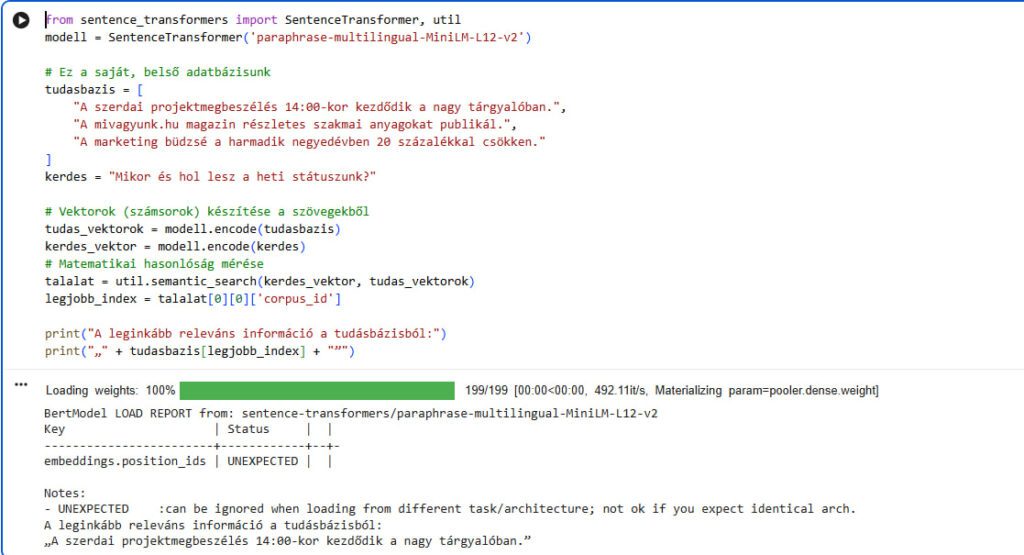
!pip install sentence-transformers. Ez letölti azt a modult, amely képes a magyar nyelvet is értelmező matematikai beágyazásokat elvégezni. - A tudásbázisod betöltése: Nyiss egy új kódcellát, és adjuk meg a rendszernek, miből dolgozhat. Másold be a következőt:
from sentence_transformers import SentenceTransformer, util
modell = SentenceTransformer('paraphrase-multilingual-MiniLM-L12-v2')
# Ez a saját, belső adatbázisunk
tudasbazis = [
"A szerdai projektmegbeszélés 14:00-kor kezdődik a nagy tárgyalóban.",
"A mivagyunk.hu magazin részletes szakmai anyagokat publikál.",
"A marketing büdzsé a harmadik negyedévben 20 százalékkal csökken."
]- A kérdés megfogalmazása és a vektorizálás: Most tegyünk fel egy olyan kérdést, ami nem tartalmazza az adatbázis pontos szavait, de értelemben kapcsolódik hozzájuk. Folytasd a kódot:
kerdes = "Mikor és hol lesz a heti státuszunk?"
# Vektorok (számsorok) készítése a szövegekből
tudas_vektorok = modell.encode(tudasbazis)
kerdes_vektor = modell.encode(kerdes)- A találat kiértékelése: Végül utasítjuk a gépet, hogy keresse meg a leginkább egyező jelentést, és írja ki nekünk.
# Matematikai hasonlóság mérése
talalat = util.semantic_search(kerdes_vektor, tudas_vektorok)
legjobb_index = talalat[0][0]['corpus_id']
print("A leginkább releváns információ a tudásbázisból:")
print("„" + tudasbazis[legjobb_index] + "”")Ha mindent jól csináltál, és lefuttatod a cellát, a rendszer ki fogja írni a szerdai projektmegbeszélésről szóló mondatot. Látod az összefüggést? A kérdésedben nem szerepelt a „szerda”, a „projekt”, de még a „tárgyaló” szó sem. A gép nem a karaktereket egyeztette, hanem a mondatok mögöttes jelentését kötötte össze. Pontosan ezen a matematikai alapelven nyugszanak a legkomplexebb, millió dolláros vállalati rendszerek is.
Értékelés és folyamatos finomhangolás
A prototípus elkészítése csak a munka kezdete egy komoly projekt életciklusában. A professzionális mérnöki tevékenység elválaszthatatlan része az értékelés (evaluation) és a tesztelés. Amikor több ezer dokumentummal dolgozol, folyamatosan mérned kell, hogy a rendszer a megfelelő darabokat emeli-e ki a vektoradatbázisból. A rossz adatdarabolás vagy a gyenge beágyazási modell oda vezethet, hogy a RAG folyamat hibás kontextust ad át a generáló modulnak, így a végeredmény is használhatatlan lesz.
A minőségbiztosítás mellett a szakemberek gyakran alkalmazzák a finomhangolás (fine-tuning) technikáját is. Ez egy sokkal mélyebb beavatkozás, mint a promptok átírása: ilyenkor a modell belső súlyozását, azaz magát a „fogaskerekeket” módosítják több ezer specifikus példa betanításával. Bár ez a lépés rendkívül erőforrásigényes, olyan speciális területeken, mint az egészségügyi diagnosztika vagy a jogi szövegelemzés, elengedhetetlen a maximális pontosság eléréséhez.
Az eszközök fejlődése és a nyílt forráskódú megoldások terjedése ma már bárki számára elérhetővé teszi ezt a tudást. Ha elsajátítod a beágyazások, az adatdarabolás és a szemantikus keresés logikáját, egy lépéssel a puszta felhasználók előtt jársz majd, és képes leszel valódi üzleti értéket teremteni az adatokból.



